Some interesting things to read for the end of the year #6
/ 6 min read
Hi, it’s Febi here with what will likely be our final weekly roundup for the year. I wish you all a joyful and prosperous new year ahead!
In today’s edition:
- 🦦 Apple enters the LLMs race - new Multimodal LLM is out!
- 🐍 🤖 Transformers against the world (Mamba, StripedHyena, RWKV)
1. Apple releases Ferret - Refer and Ground Anywhere at Any Granularity
Compact, yet powerful models are always welcome. In fact, very much needed. The ability to train compact models with cutting-edge capabilities would democratize advanced AI, enabling a broader range of individuals and organizations to study and deploy them, instead of being an exclusive domain of a few with vast computational resources — overall better for the pocket and environment alike.
a) LLM in Flash
LLM in Flash: https://arxiv.org/abs/2312.11514 - this particular paper introduces a framework to overcome current LLMs shortcomings: they are large and require a lot of memory. Making it difficult to run them on devices with limited DRAM e.g a 7 billion parameter model requires over 14GB of memory just to load the parameters in half-precision floating point format.
Proposed solution? → Store the model parameters on flash memory. By exploiting sparsity in the FeedForward Network (FFN) layers and selectively loading only necessary parameters from flash memory - plus employing additional two techniques called (a) “windowing” which is loading parameters for only the past few tokens and reusing activations from recently computed tokens, and (b) “row-column bundling” which roughly translates into “reading larger chunks to increase throughput”. This solution resulting in increase in inference speed by 20-25x compared to naive loading approaches in CPU and GPU as well as demonstrating the ability to run LLMs up to twice of the size of available DRAM, paving the way for wider LLM deployment on resource-constrained devices.
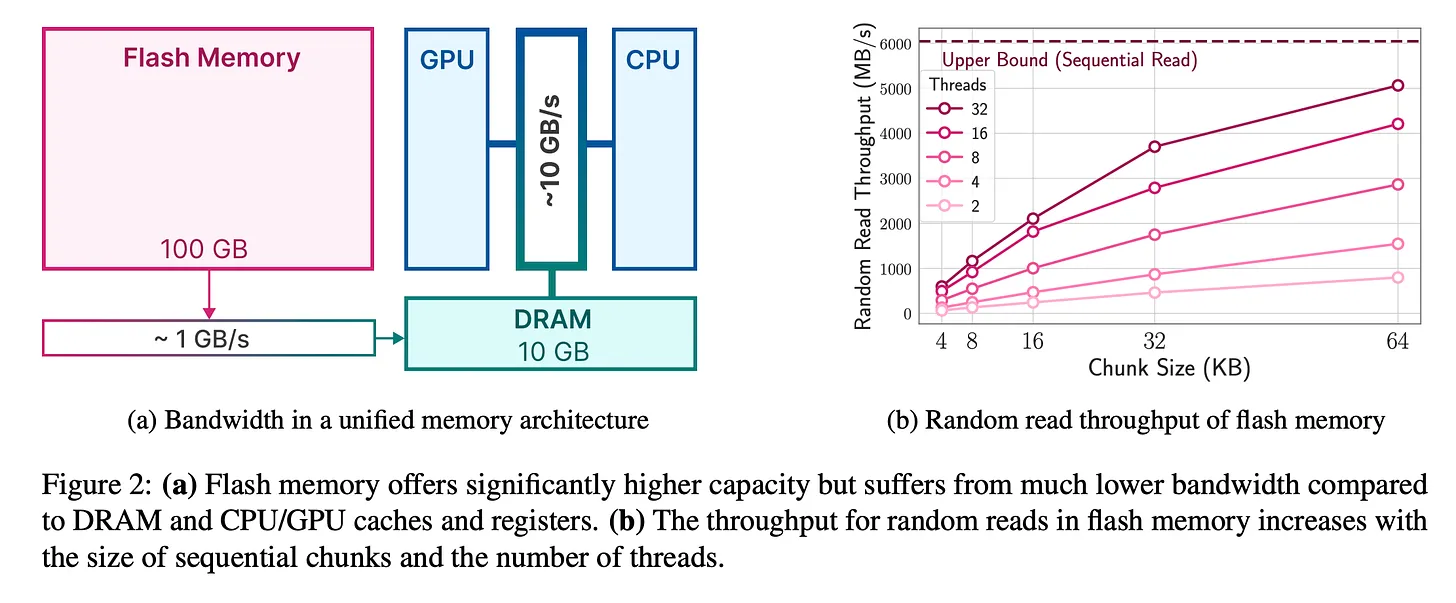 Image Source: Paper: https://arxiv.org/pdf/2312.11514.pdf
Image Source: Paper: https://arxiv.org/pdf/2312.11514.pdf
b) Ferret
Ferret: https://arxiv.org/abs/2310.07704 - this paper introduces Ferret, a Multimodal Large Language Model (MLLM) capable of understanding spatial referring of any shape or granularity within an image and accurately grounding open-vocabulary descriptions — meaning it can point out details as specific as “the cat under the table” — much like giving LLMs a magnifying glass and a pointer. Ferret was built on top of Llava and Vicuna. It appears to be Apple’s answer to Google’s Gemini, potentially setting the stage for a fierce rivalry in the realm of multimodal LLMs. Here’s a TL;DR:
 Image Source: Paper: https://arxiv.org/pdf/2310.07704.pdf
Image Source: Paper: https://arxiv.org/pdf/2310.07704.pdf
Problems
- Vision-language models need better spatial understanding (knowing where things are in an image)
- Two important skills for this are referring (describing specific regions) and grounding (finding regions based on descriptions)
- Current models usually learn these skills separately, but humans learn and use them together seamlessly
Objectives
- Develop a model that can unify referring and grounding in a single framework, much like humans do.
- The model should be robust and practical by:
- Representing different types of regions (points, boxes, scribbles, freeform shapes).
- Working with open-vocabulary instructions — not just pre-defined words.
- Following complex instructions involving both text and regions.
Key Innovations:
- Unified framework: Combines referring and grounding using shared knowledge.
- Hybrid region representation: Uses both discrete coordinates (like “top-left: (10, 5)”) and continuous visual features (from the image) to represent any shape.
- Spatial-aware visual sampler: Extracts features from regions of any shape, even sparse ones like scribbles.
- Free-form input: Can handle instructions containing both referred regions and text descriptions.
- Simultaneous generation: Outputs both text and coordinates for grounded objects.
All in all, I’m glad Apple seems to be further ahead in ML than I thought.
2. Transformers against the world - towards cheaper, and scalable architectures
2023 is without a doubt, the year of Transformers. However, as we advance towards 2024, a thrilling shift with the emergence of other new architectures such as RWKV (Receptance Weighted Key Value), StripedHyena, and Mamba have emerged, each offering new scaling laws for training, different inference costs, and many other things.
There are some reasons why attention, the bedrock of Transformers became the de facto architecture today, but the capabilities of these newcomers raise a question: is it time to take other architectures more seriously?
Imagine training models on massive datasets without sweating over memory constraints - that’s the promise from models the likes of RWKV which combines the strengths of RNNs and Transformers. So does Mamba, as we’ve talked in the previous roundup, which unlocks blazing-fast inference speeds (5x higher throughput than Transformers) as well as linear scaling in sequence length (up to million-length sequences) and StripedHyena was assembled from many advancements including S4 and many lesson learned from the previous architectures: H3, Hyena, HyenaDNA, and Monarch Mixer.
From this slide by Sasha Rush, I think we can see where it’s headed: an RNN Revival.
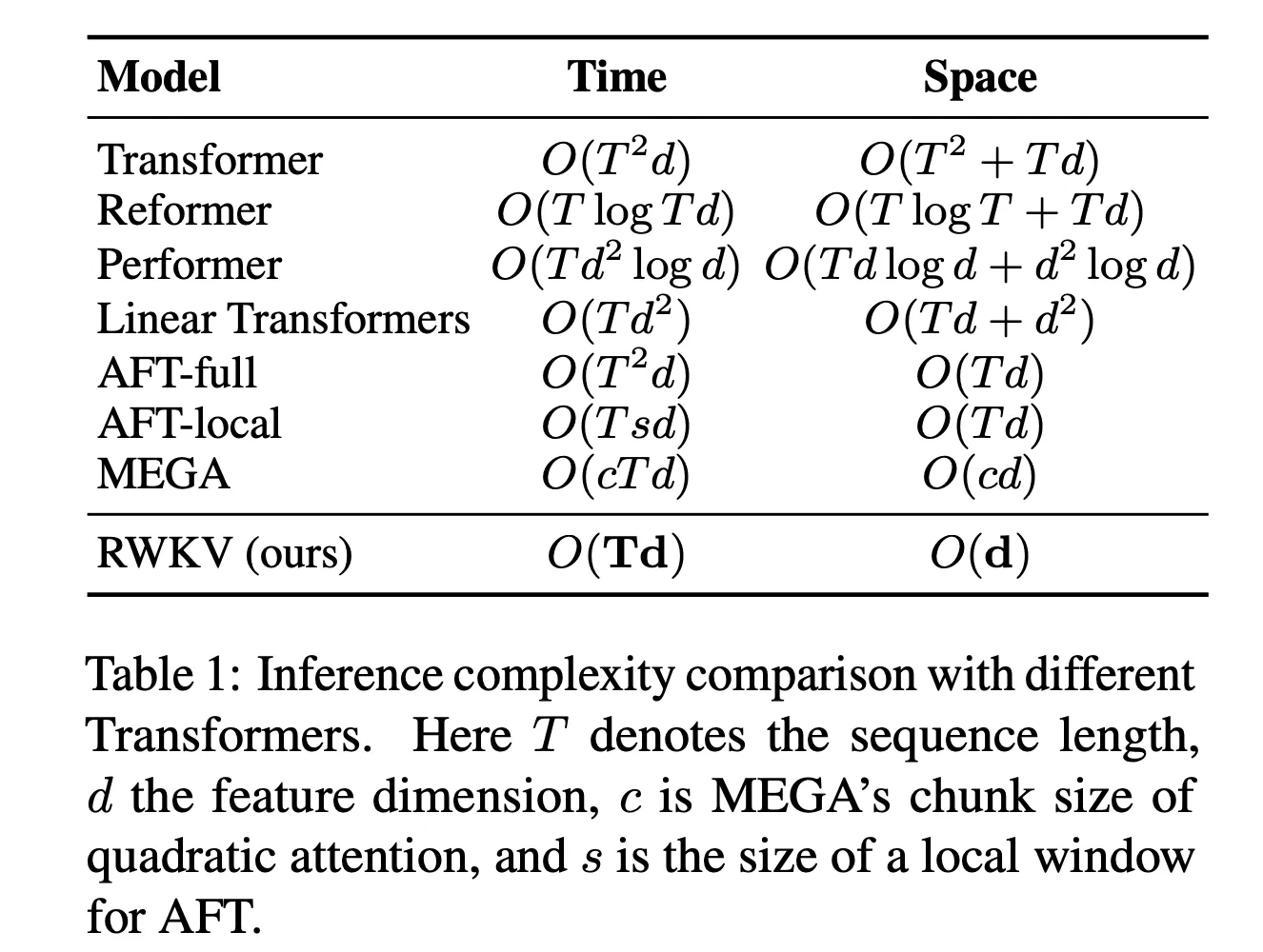 Image Source: Paper: https://arxiv.org/abs/2305.13048
Image Source: Paper: https://arxiv.org/abs/2305.13048
Now, pretty much anyone in the space knows that attention is likely to be replaced - in fact some people are racing towards replacing it.. what we don’t know yet is by what (RNN?), and when (4 years?). Recent developments have shed a light on some of the strong contenders like the above but it will likely take more time than we expected. (when is time became an issue in this space? cause everyone seems to be moving very fast) Moreover, now that we’ve seen people pushing the boundaries by not only exploiting the architecture in the software realm, but also in the optimizing the hardware parts, the future architecture will not only need innovations in software but also investments in a new-kind infrastructure.
 Image Source: Sasha Rush
Image Source: Sasha Rush
Please also take your time to read a primer in this area by none other than Nathan Lambert.
Charts that caught my attention
 Source: EveryPixel (2023 the year of AI)
Source: EveryPixel (2023 the year of AI)
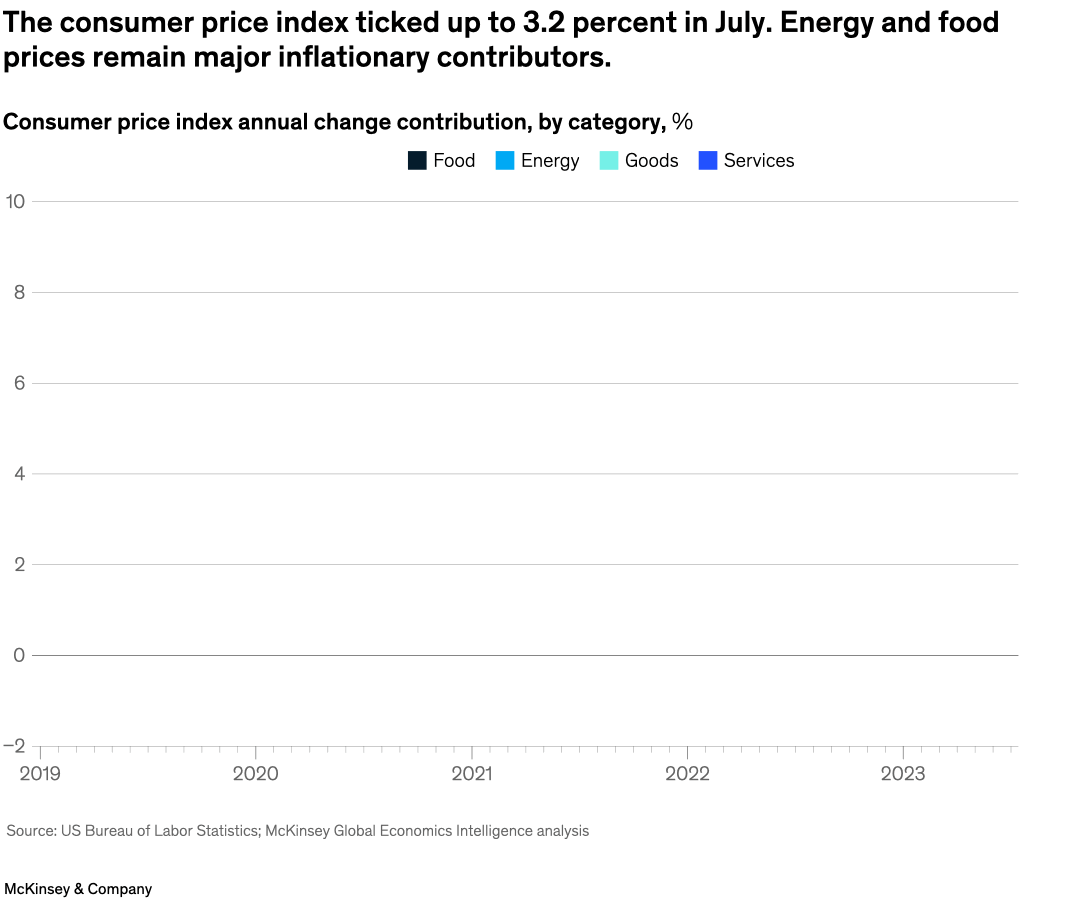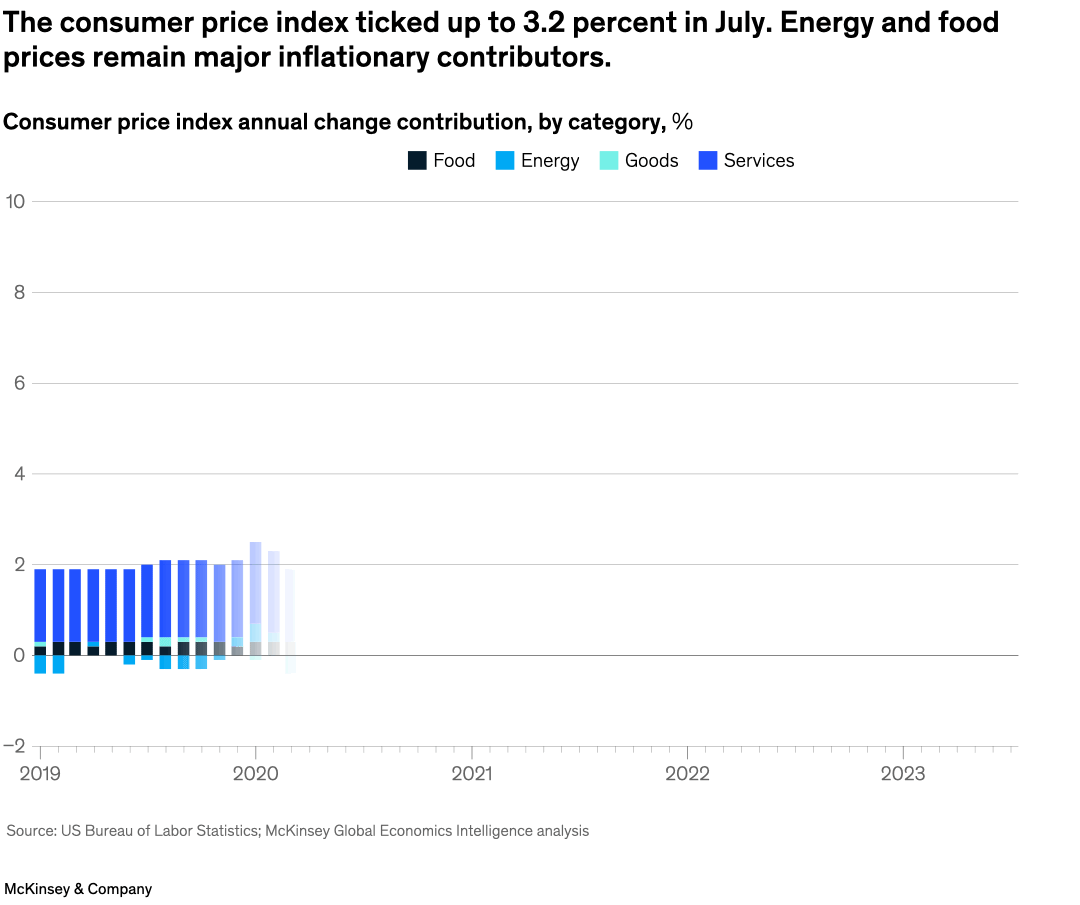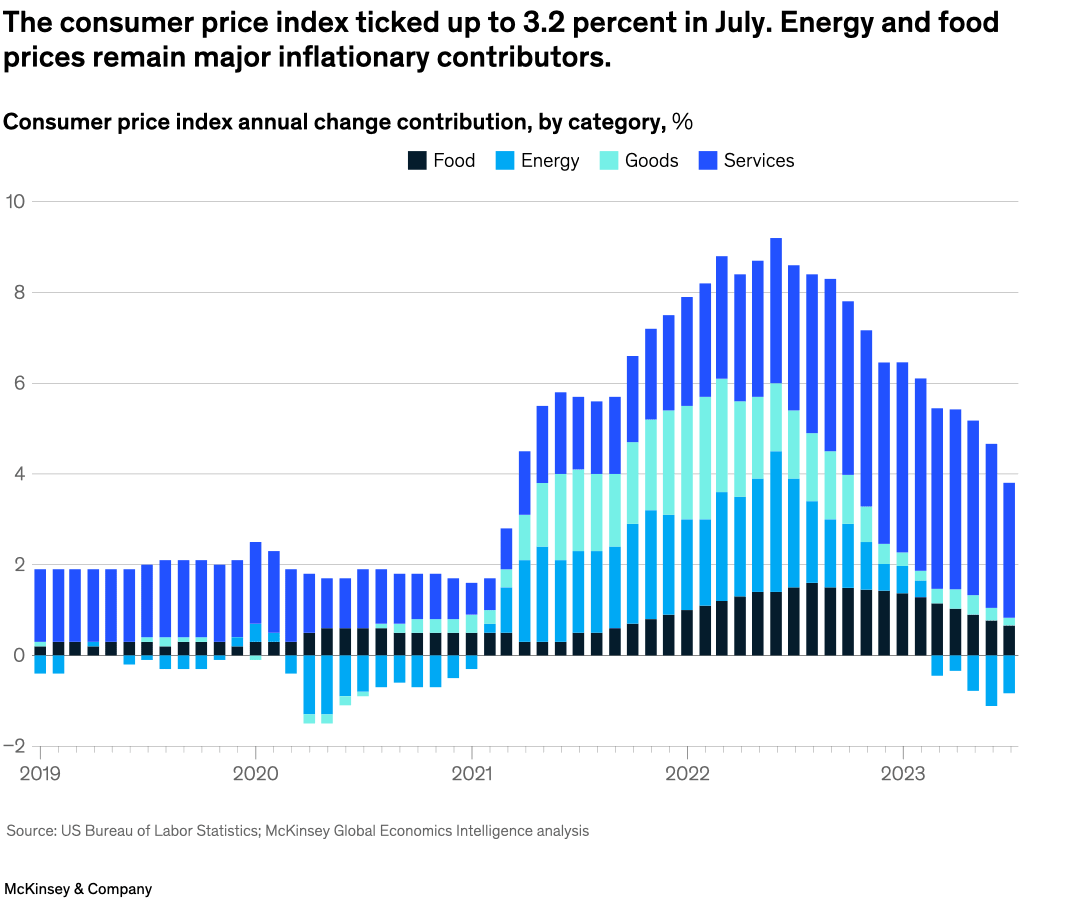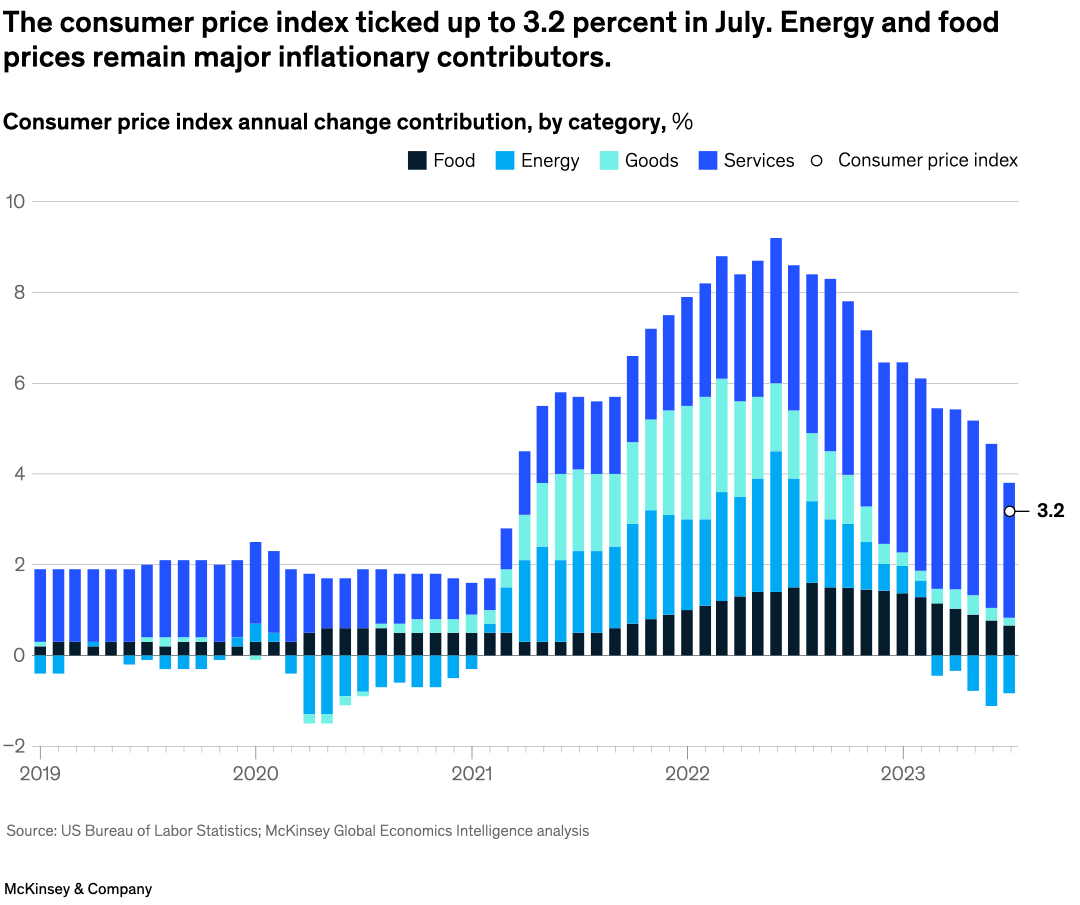 Source McKinsey & Company
Source McKinsey & Company
Other Reads
AI Papers
-
The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction - Neural networks can often have well over 90% of their weights removed without any significant degradation in performance. In this paper, there’s a new interesting finding: careful pruning done at specific layers of Transformer models can even produce significant boosts in performance on some tasks. Even better, this discovery appears to not be limited to natural language, with performance gains also found in reinforcement learning.
-
ReSt meet React - Defining a ReAct-style LLM agent with the ability to reason and act upon external knowledge, and refine the agent through a ReST-like method. After just two iterations, achieves comparable performance to other models but with fewer parameters.
-
Pangu-Agent - Inspired by the modularity of the human brain, researchers from Huawei Noah’s Ark Lab, University College London, and University of Oxfords developed a framework that integrates Large Language Models (LLMs) to address reasoning and decision problem towards building generalist agents.
Other interesting stuff
- 2023: A year in charts (McKinsey)
- Major LLM services visits reach about 2bn combined (Tweet)
- Nuclear Fusion Breakthrough (Independent)
- What I wish someone had told me (Sam Altman)
- American brain drains China’s talent (Noah Smith)
- The simplest explanation isn’t always the best. Dimensionality reduction can see structures that do not exist and miss structures that exist.
- Cancer-fighting CAR-T cells could be made inside body with viral injection (Nature)
- ByteDance secretly used OpenAI’s API to build their own LLM (The Verge)
- Samsung’s new AI-enabled smart fridge can design recipes based on your dietary needs (The Verge)
I’ll return next year. Happy New Year! 🎉🎉