Some interesting things to read in the middle of the week #4
Gemini launch, TPUv5 - AI Hypercomputer, Mistral dropped bombs, Mixture of Experts, and Mamba for accessible AI development
This post is also published on my newsletter, Superficial Intelligence here
Hi, it’s here with our somewhat regular weekly roundup. Which was overdue by 5 days.
In today’s edition:
- Gemini launch and OSS Models storming the AI space 🚀💥
- Mixture of Experts 🧑🔬
- Mamba 🐍🐍 - state-space models
1. A Tale of Two Launch: Gemini and Mistral
 Image Source: DALL-E
Image Source: DALL-E
I can’t help but thinking.. what a time to be alive. It seems every day that we witness a (albeit sometimes small but continuous) progress in AI. Some advancements subtly nudge the field forward, while others, like bolts from the blue, redefine what we thought possible. This week has been full of the latter.
Enter the long-promised Gemini, an AI model that's been shrouded in anticipation is finally out, and the expectations? They’re sky-high!
Gemini surpasses SOTA (State of the Art) performance on all multimodal tasks. - Google DeepMind
The Gemini family consists of Ultra, Pro, and Nano sizes tailored for various use-cases. The smallest ones, Nano-1 (1.8B) and Nano-2 (3.25B) were the most-efficient models and designed to run on-device. Evaluation on a broad range of benchmarks shows that the most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 of these benchmarks.
Google seems to deliver what they have been promising since Google I/O in May —Gemini’s built from the ground up for multimodality that reasons seamlessly across text, images, video, audio, and code — which is a respectable force against GPT-4. Suffice to say that it’s kind of a relief that they finally deliver before the changing year because prior to the release, there’s a rumor going around about its delay. DeepMind’s achieving SOTA in many benchmarks however - without undermining their works, comes as no surprise given their track records. They should’ve been the leader in the space after all. If any organizations can achieve AGI, Google would be top of mind. Think about it — DeepMind's track record is like the greatest hits of AI breakthroughs. From the legendary AlphaGo to the revolutionary AlphaFold, and the recent GNoME project, they've consistently raised the bar. Even Pre-trained Transformers was born and raised at Google.
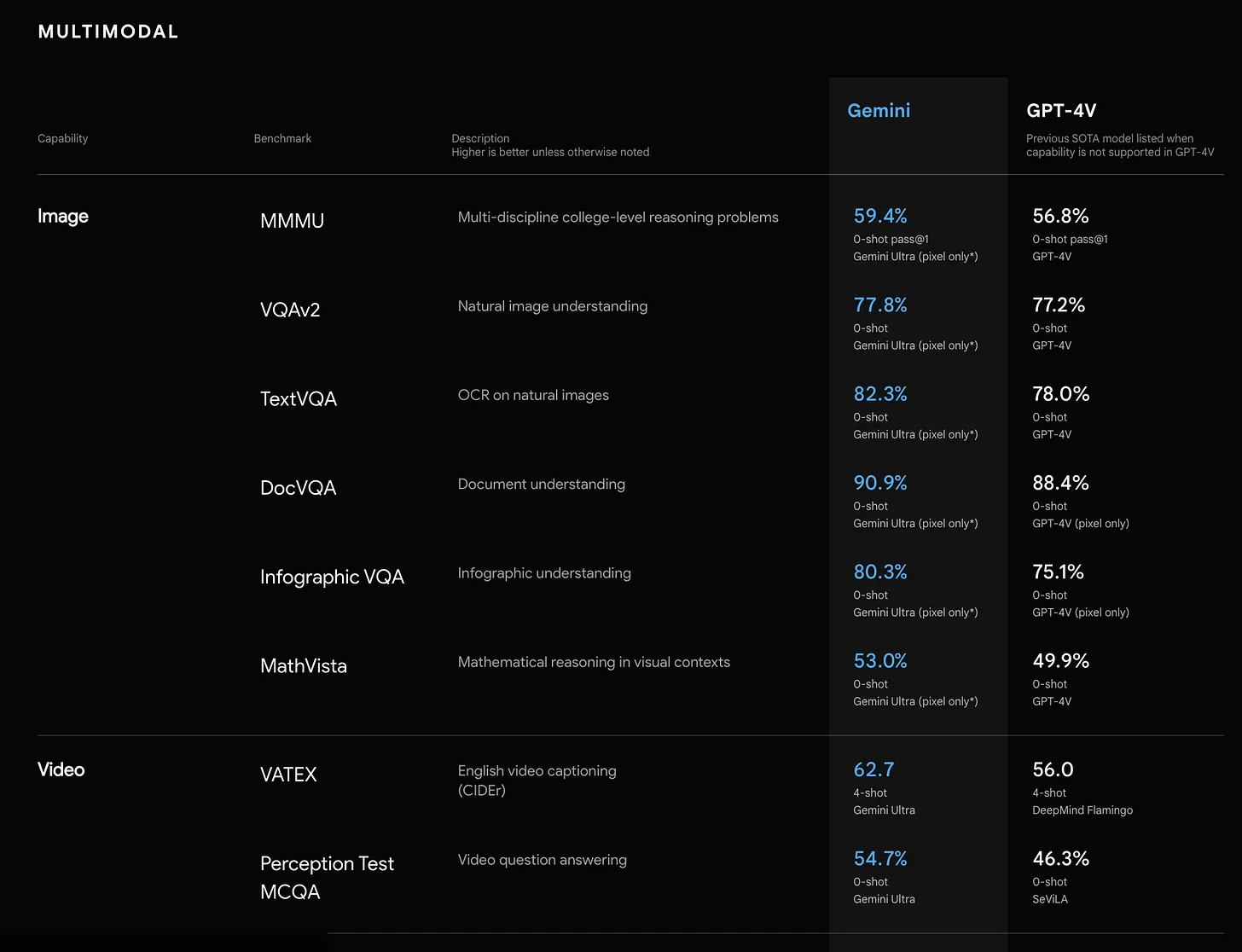
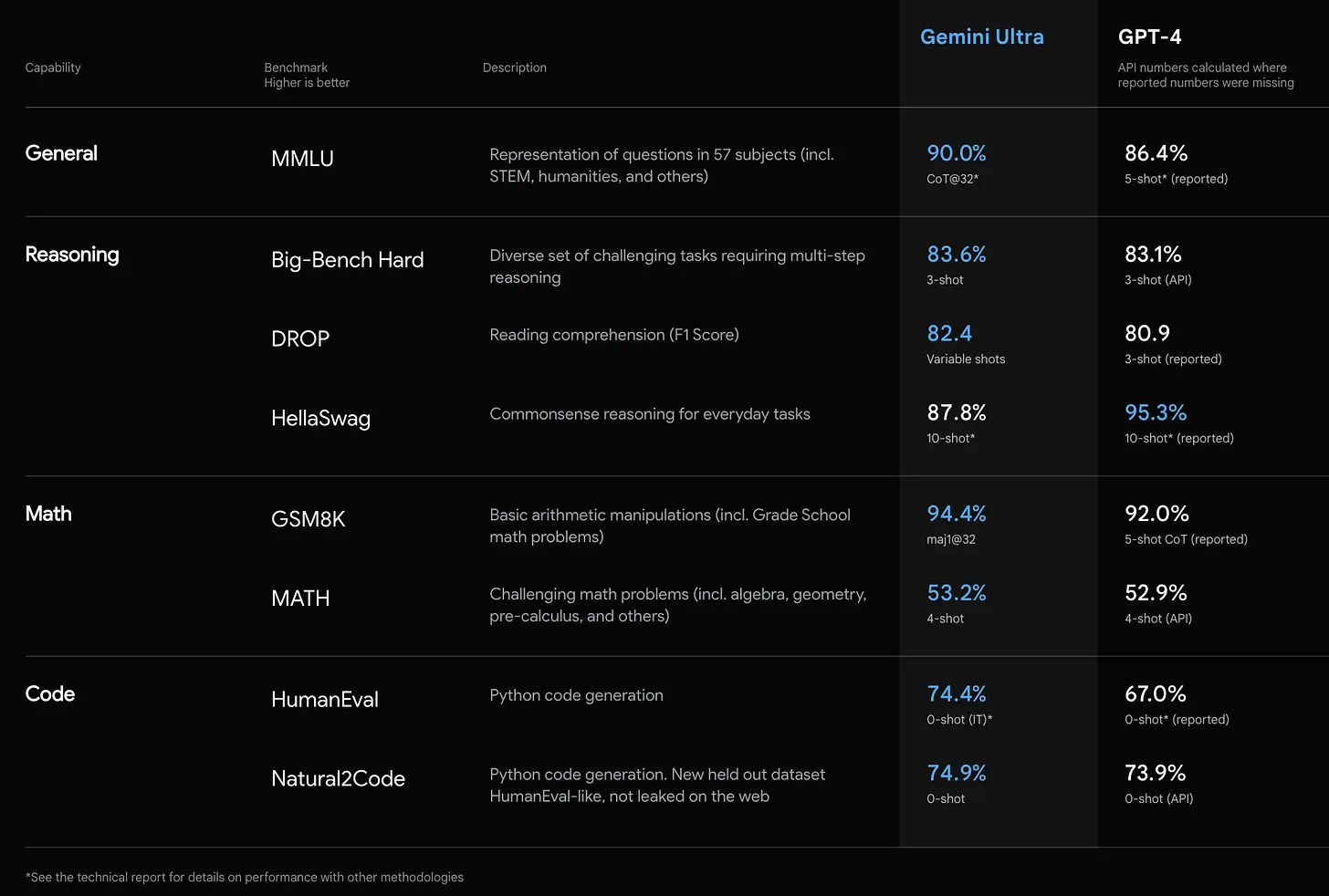 Above: Multimodal benchmark performances, Below: Text-focused benchmark performances. Source: DeepMind
Above: Multimodal benchmark performances, Below: Text-focused benchmark performances. Source: DeepMind
What’s so surprising though, how narrow the gap is between Gemini 1.0 and GPT-4 which was launched many months ago. While I think what they have accomplished — putting out a worthy rival to GPT-4 — by every definition was a big feat, I expect a lot more from the built-in multimodality, but hey it’s still in its 1st version. So I’m really looking forward for the next iterations.
However, it's noteworthy to bring up how Google felt the need to stage their demo video and cherry-pick their performances against benchmarks, which invited lots of criticism and casted a lot of doubts about the real performance of Gemini. Such a move reflects the intense competition and the high stakes in demonstrating technological prowess in the AI arena.
What particularly interesting for me is Gemini’s integration with Google’s ecosystem. One by one, Google is unveiling its “Gemini”-powered products & technologies, starting from Bard, of course. Then there is AlphaCode 2, an improved version of the code-generating AlphaCode, which reportedly scored better than 85% of programmers who participated in solving similar coding problems — Obviously better than me!
Google has also brought Gemini into Pixel 8 Pro, offering several advantages to the smartphone owners, from summarization features, smart replies in Gboard, to AI-powered photos and videos.
I'm particularly interested in the technical choices and challenges involved in creating these models. As the first of its kind, training Gemini required innovations in training algorithms, dataset, and infrastructure. This wasn’t about merely scaling up existing methods. The Gemini models were trained using Google’s own chips - TPUv5e and TPUv4, with the larger Gemini Ultra model utilizing numerous TPUv4 accelerators across several datacenters, a significant scale-up from the previous PaLM-2 model.
The TPUv4 accelerators are deployed in “SuperPods” of 4,096 interconnected chips that can dynamically reconfigure to maximize performance. For Gemini Ultra, a small number of cubes per SuperPod were retained for redundancy and rolling maintenance. SuperPods are combined across datacenters using Google’s network utilizing model parallelism within SuperPods and data parallelism across SuperPods. The programming model of Google's Jax and Pathways allows simpler configuration and orchestration of training runs. Optimizations in XLA's compiler maximize performance and minimize variation in step times. In addition, instead of checkpointing weights to persistent storage periodically, Gemini utilizes redundant in-memory model replicas for faster failure recovery and uninterrupted training.
The overall goodput for the largest-scale training job increased from 85% to 97%. — Google DeepMind
Through these optimizations, for the largest Gemini Ultra training runs, the percentage of time where useful training work was happening increased from 85% to 97% compared to their previous model, PaLM-2.
To summarize, the training of the Gemini models was a remarkable feat of engineering. It demonstrated Google Cloud’s capabilities as a highly scalable and versatile AI infrastructure platform. That’s why they launch Google AI Hypercomputer the day after Gemini’s launch, aiming to provide this infrastructure beyond Google.
There’s no doubt Google has made striking progress across many fronts like the Gemini models, new TPUv5 chips, expanding ecosystem integrations, and many others at the same time. However I can’t help but get this sense that all these technical achievements have somehow felt overshadowed. Much of the focus has shifted to the debates over the preliminary demo’s factual accuracy, and transparency concerns. What could’ve been a spotlight on impressive advancements, yet again ended up as PR missteps.
 Source: X
Source: X
Mistral, an AI startup from french, though… took an opposite direction from Google. Instead of carefully orchestrated demo, they quitely shared a direct access to the model weights.. via torrent.. twice.
But what’s so special? There are dozens of models coming out every month, right?
Aside from doing the swag release:
- Drop a magnet link with no fanfare
- Surprise everyone with a pull request to the open-source vLLM project to help the community integrate the Megablocks CUDA kernels.
- Release the blog post with an impressive feat
- and..
What I think Mistral did it right as well lies in their focus on optimizing 7B-tier models and focus on wider accessibility, rather than chasing ever-larger models. They also focus on what’s important: gathering feedback from the customers, iterate fast, and monetize the model through their platform ASAP - a la OpenAI. And like an overnight success they have secured another $415million. Everything somehow clicked.
Mixtral is a powerful and fast model adaptable to many use-cases. While being 6x faster, it matches or outperform Llama 2 70B on all benchmarks, speaks many languages, has natural coding abilities. It handles 32k sequence length - Mistral
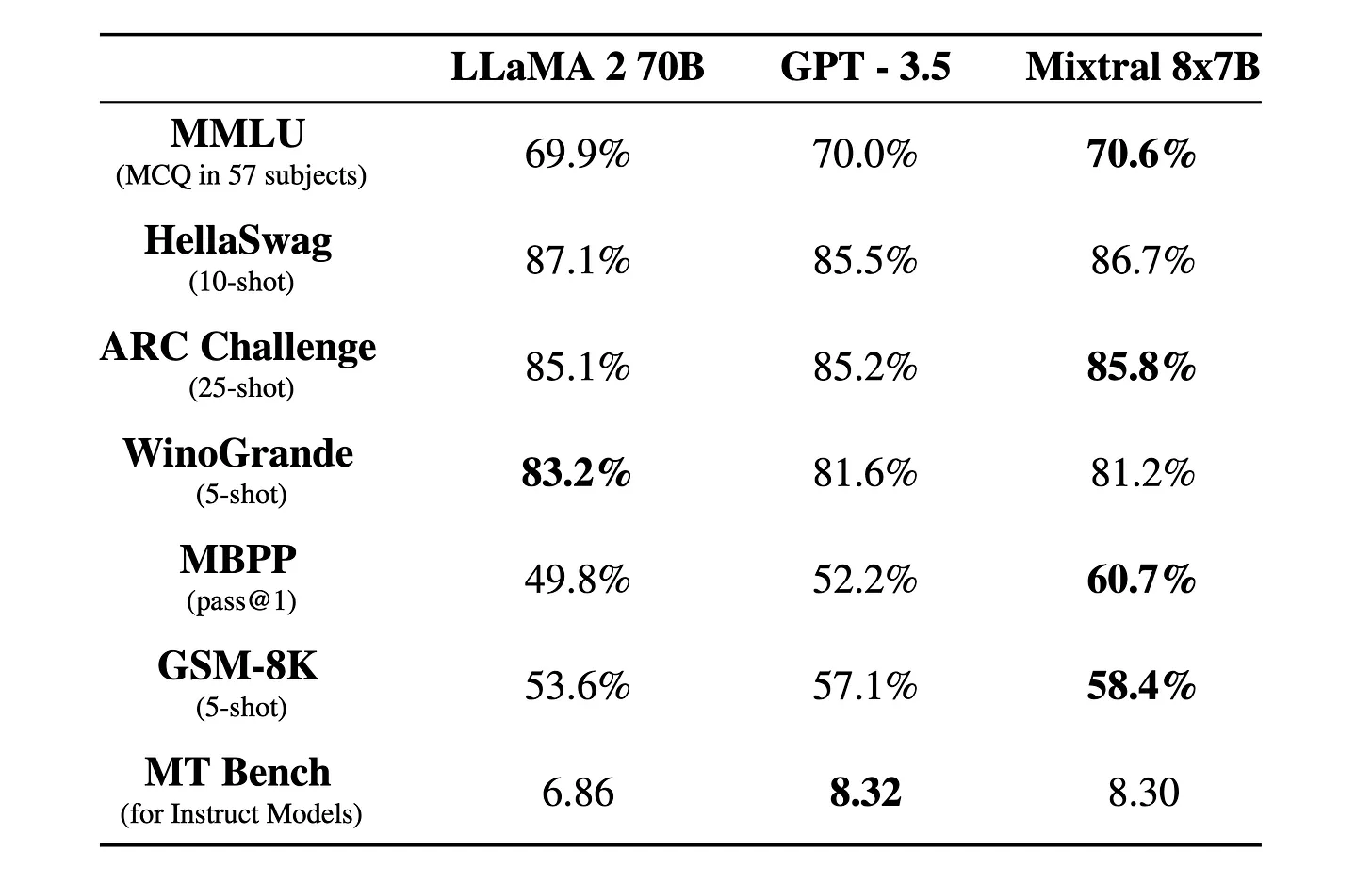 Source: Mistral's Blog
Source: Mistral's Blog
At first no one knows how to use the weights. The journey of unlocking Mistral’s models power was a collective one. People hand in hand figuring out and share their progress in unlocking the models — like a global puzzle party, and as it unfolded.. people just realized how much power Mistral has unleashed to the public.
It feels like an inflection point. Finally a GPT-3.5 level model that can run at 30 tokens/sec on an M1! right? (I haven’t tried it, btw. But I wish that was true).
 Source: Source: Brian Roemmele, credit: ARKInvest
Source: Source: Brian Roemmele, credit: ARKInvest
Anyway, the above chart paints a promising picture: open-source models are closing in on GPT-4, and parity feels just around the corner. However, GPT-4 can be seen as an outlier, and the significant jump from GPT-3.5 to GPT-4 is unprecedented. So we can expect that there would be a bit of a hurdle to go from GPT-3.5 level to GPT-4 in “real-life” performance - even Gemini Ultra is still being cooked up. Although to be fair, I’ve been playing with the newly Gemini-powered Bard and it feels a lot better - so my expectations are high.
Going back to Mistral. Like Google’s Gemini family, Mistral provides three endpoints:
- Mistral-tiny. The budget-friendly option, powered by Mistral 7B Instruct v0.2, tackles English tasks with efficiency.
- Mistral-small. This endpoint currently serves their newest model, Mixtral 8x7B. Aces English, French, Italian, German, Spanish, and code, scoring an impressive 8.3 on MT-Bench.
- Mistral-medium 👀. Their highest-quality endpoint, a prototype model, dominates in English, French, Italian, German, Spanish, and code, boasting an 8.6 MT-Bench score.
I don’t think it’s an exaggeration to say that Mistral has rapidly became the new darling in the OpenLM community…
2. Mixtrals of Experts and Mamba’s State-Space Models

We have seen from the above that Mistral's latest models boast an impressive performance-to-parameter ratio, which make use easily raise eyebrows. How are they punching above their weight compared to models 10-25 times larger?
Fortunately, with the released official blog, now we know almost exactly what’s going on under the hood. Mistral matches or even outperforms Llama 2 70B & GPT3.5 by employing Mixture of Experts - such a clever naming from Mistral: Mixtral of Experts.
You know, when we talk about tinkering and advancing AI nowadays, it feels like a billionaire’s playground — something that only the ultra-wealthy can do, and thanks to the Scaling Laws (a.k.a bigger is better) that suggested increasing model size led to reliable and predictable improvements in capability, a trend of boasting trillions of parameters of neural nets are the new status symbol, leaving garage inventors in the dust.
So the effort of shrinking the models parameter while preserving (or even improving) performance, through Mixture of Experts and other alternative like state-space models, which we will talk about in a moment, are very needed innovations. These alternatives offer promise for more inclusive AI progress.
So what is Mixture of Experts (MoE)?
TL;DR
MoEs:
- Are pretrained much faster vs. dense models
- Have faster inference compared to a model with the same number of parameters
- Require high VRAM as all experts are loaded in memory
- Face many challenges in fine-tuning, but recent work with MoE instruction-tuning is promising
Key Components:
- Experts: MoE layers consists of many experts, small MLPs or complex LLMs like Mistral 7B.
- Router: There are two routing strategies: token chooses the router or router chooses the token. How does it work exactly? It uses a softmax gating function to model a probability distribution through experts or tokens and choose the top k.
Traditional deep learning models use one set of parameters for all inputs. Mixture of Experts (MoE) models are different - they choose different parameters for each input example. This allows them to specialize parts of the model for different inputs. Even though MoE models have a very large number of possible parameters, they still take about the same amount of computation to run. The specialized parts only activate for the right inputs. This flexibility helps MoE models handle complex data more efficiently.
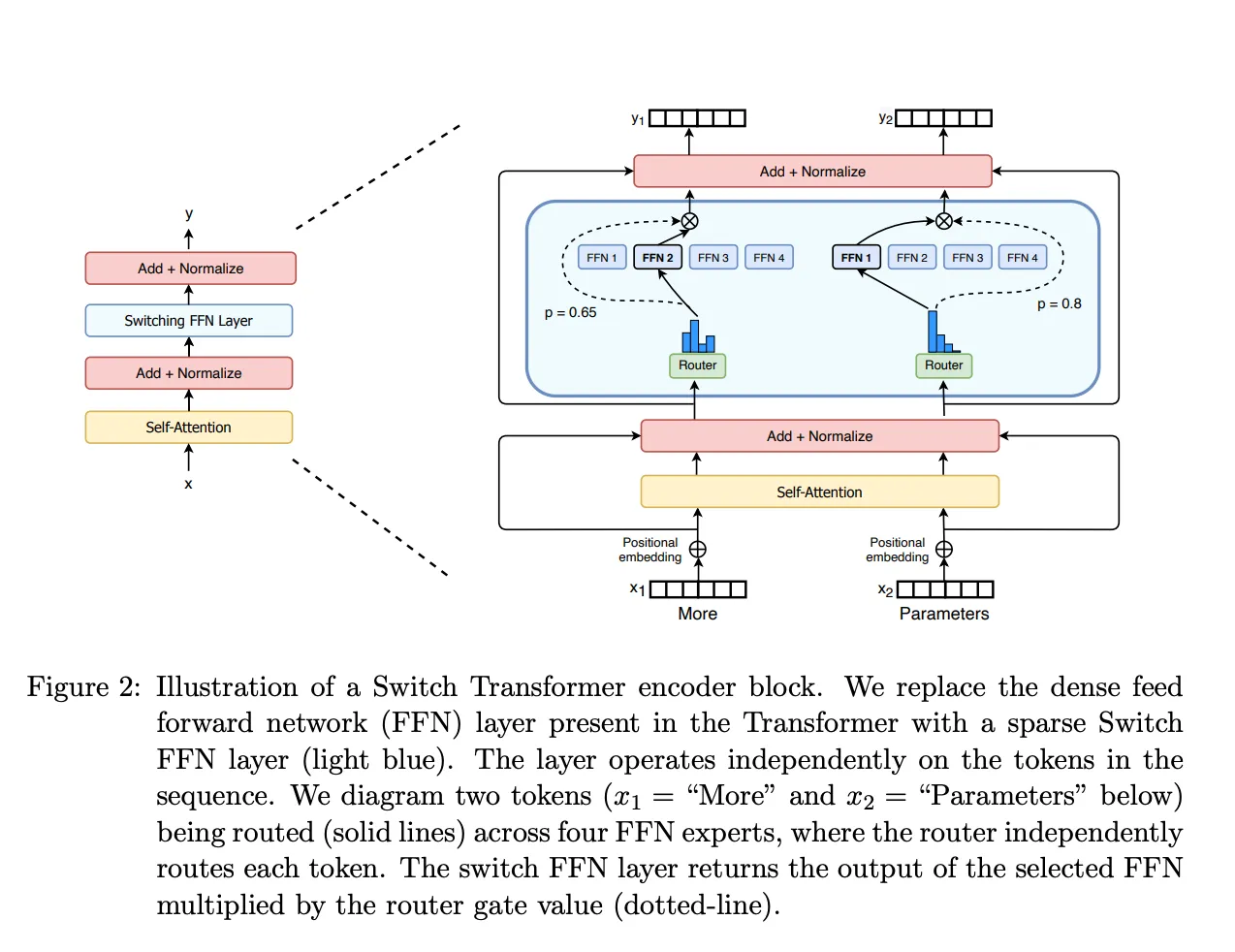 MoE Layers. Source: Switch Transformers paper
MoE Layers. Source: Switch Transformers paper
Mixtral is a decoder-only model that utilizes a form of expert routing as well. In its feedforward layers, Mixtral selects two out of eight distinct expert parameter groups to process each token. The experts here can be viewed as smaller ML models with their own specialized parameters.
A key component is the router network, which determines which two experts are selected per token and layer. The routing strategy models a probability distribution over experts and tokens using a softmax gating function. Based on this distribution, the top k experts are chosen for each token.
This routing approach allows Mixtral to scale up to 46.7 billion total parameters, while only employing 12.9 billion per token. So despite having more overall parameters, Mixtral can process inputs and generate outputs at the same speed and cost as a 12.9 billion parameter model.
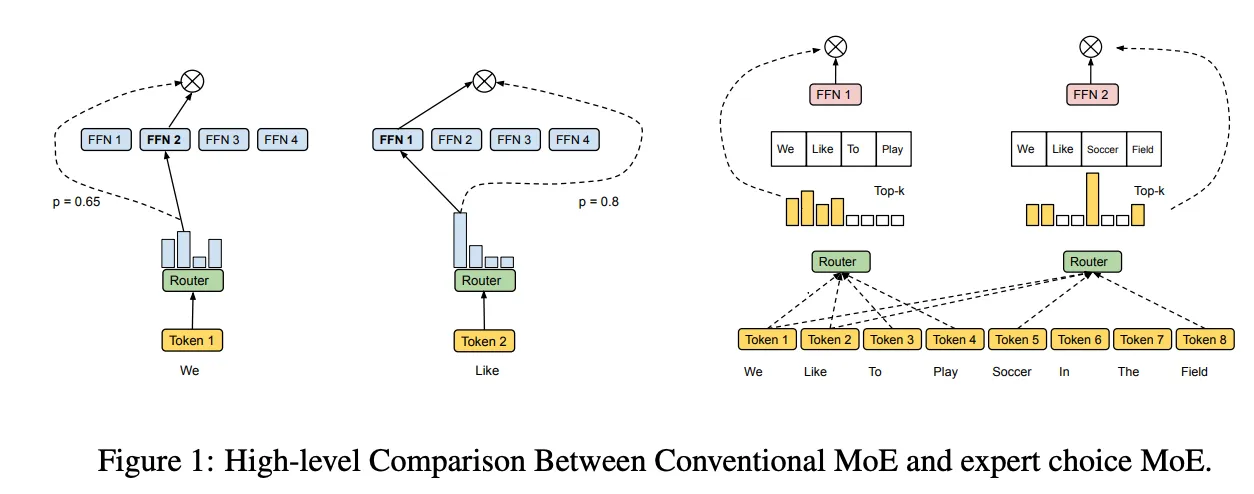 Source: Mixture of Experts with Expert Choice Routing
Source: Mixture of Experts with Expert Choice Routing
If you have time, please read the whole explanation about MoE here.
And what is Mamba?
Foundation models (FMs) — large models pretrained on massive data then adapted for downstream tasks — have become a key paradigm in machine learning. These models, often sequence-based, handle diverse domains like language, images, and genomics. Primarily based on the Transformer architecture and its attention mechanism, they excel in complex data modeling within a context window. However, they face limitations like finite window size and quadratic scaling with window length. Although research has focused on more efficient attention variants, none have yet matched the effectiveness of the original model at scale across different domains.
Structured state space sequence (S4) models offer highly scalable inference performance. They operate with constant memory and time usage per step, irrespective of sequence length. While LSTMs and other RNNs share this scalable property, S4 models outperform them in terms of efficiency and are also parallelizable across sequence dimensions during training, making them more effective for handling long sequences.
In the paper titled "Mamba: Linear-Time Sequence Modeling with Selective State Spaces" the author introduces Mamba, a new architecture for sequence modeling. It enhances structured state space models (SSMs) by incorporating a selection mechanism, allowing the model to selectively propagate or forget information based on input content. This design addresses the computational inefficiency of transformers on long sequences and enables content-based reasoning.
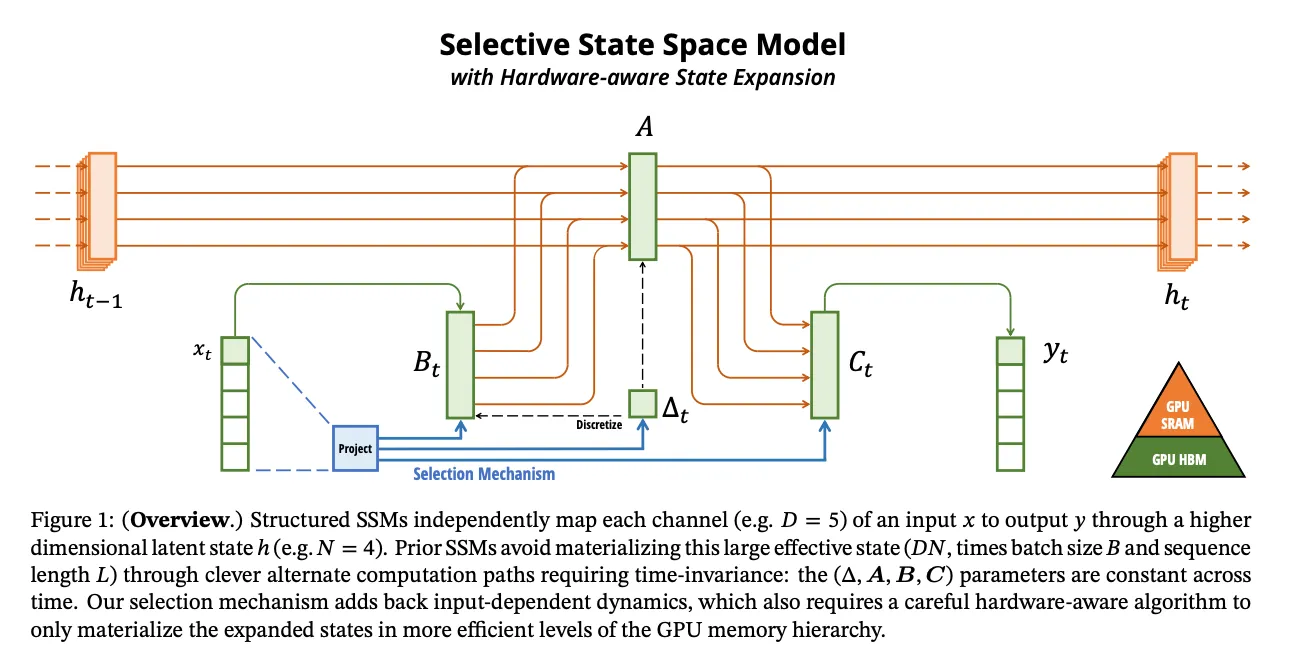 Source: Mamba paper
Source: Mamba paper
Mamba's selective SSMs offer several improvements:
- Selection Mechanism: Enhances SSMs by parameterizing them based on input, enabling selective information propagation.
- Hardware-Aware Algorithm: Overcomes computational challenges of the selection mechanism through a hardware-aware parallel algorithm, ensuring faster performance ((up to 3× faster on A100 GPUs).
- Simplified Architecture: Mamba integrates selective SSMs into a unified architecture without attention or MLP blocks, achieving linear scaling in sequence length and high throughput.
Mamba demonstrates state-of-the-art performance across multiple modalities like language, audio, and genomics. Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Its linear-time complexity, combined with robust performance, makes it a strong candidate for general-purpose sequential foundations models. What’s more interesting is that it can leverage a very long context (up to 1 million tokens).
In comparison to Mixture of Experts (MoE):
- Scalability: Mamba scales linearly with sequence length, while MoE's scalability is dependent on the number of experts.
- Complexity: Mamba's selective mechanism simplifies architecture, whereas MoE requires managing multiple experts.
- Performance: Mamba shows strong performance across various modalities, potentially more versatile than MoE which might excel in specific tasks or domains.
- Efficiency: Mamba's hardware-aware design might offer computational advantages over MoE, especially for longer sequences.
Enough for today’s edition. The future looks so bright ☀️😎