Some interesting things to end this week #2
/ 7 min read
1. Sam Altman returns to OpenAI, Q*, and Artificial General Intelligence
Covering about the unfolding drama at OpenAI lately blurs the line and making me feel no different than a gossip writer. But it’s too difficult to ignore such a buzz. It’s the hottest thing in the tech world recently (which I also cover in my previous update)
In one of the greatest uno reverse card the history has ever seen, Sam Altman went from being the victim of coup - ousted by the board from his own company - to then landing a top stop at Microsoft to lead the specially created division only for him by Nadella. Then, in a (100th) twist, he wound up back in charge at OpenAI. One of the reason might be because 700+ out of 770 the employees threaten to leave OpenAI and follow Altman to his new venture.
This whirlwind of events at OpenAI has sparked widespread curiosity and speculation about the reasons behind such dramatic shifts. A particularly intriguing theory that I’ve come across suggests that Ilya Sutskever, the co-founder and Chief Scientist, encountered something alarming, prompting a reaction that has elicited skepticism from various corners, including Elon Musk.

The speculation doesn’t stop there, especially in the wake of a Reuters report that hints at insider claims linking Sam Altman’s departure to a significant breakthrough in Artificial General Intelligence (AGI) made by OpenAI with codename “Q*”. This only adds fuel to the speculative fire surrounding the company’s internal dynamics and the implications of their advancements. This is where things get more interesting.
2. What could OpenAI’s breakthrough Q* be about?
 Image Source: Generated by DALL-E
Image Source: Generated by DALL-E
Q* is a precursor to AGI. Really?
The enigmatic term Q* has triggered yet another flurry of speculation within the AI community. Is it truly a stepping stone toward Artificial General Intelligence (AGI)?
The name suggests a possible connection to Q-learning—a reinforcement learning technique where “Q” represents the quality of a state-action combination. One might hypothesize that Q* indicates the optimal Q-values, akin to finding the ideal solution within the Bellman equation framework. Another angle might be a hybrid approach, blending the A* search algorithm with Q-learning principles.
I recall a while back, Demis Hassabis of Google DeepMind hinted that their system, Gemini, is positioned to outpace OpenAI, by incorporating strategies from their previous triumph, AlphaGo.
Could Q* involve an AlphaGo-like Monte Carlo Tree Search, navigating the potential paths of token generation? It’s not far-fetched when you consider that existing approaches, such as those used in AlphaCode, have successfully applied naive brute force techniques within a language model to get huge improvements in competitive programming. By improving this method to sort through potential sequences of code more efficiently, we could see major improvements in areas like software development and mathematics, where you can clearly determine whether a solution is correct. I think that “Q*” relates to boosting the AI’s ability to solve complex problems, particularly those involving math.
There is also another potential reference to Q* in this particular paper.

Another thing I’d like to highlight regarding the discussion surrounding AGI is that it’s a topic that can quickly lead to diverse interpretations and expectations. The contribution by the DeepMind team in clarifying this through their paper, which outlines the various stages of AGI, is incredibly valuable. It provides a much-needed framework for understanding and measuring progress towards this formidable goal in AI research.
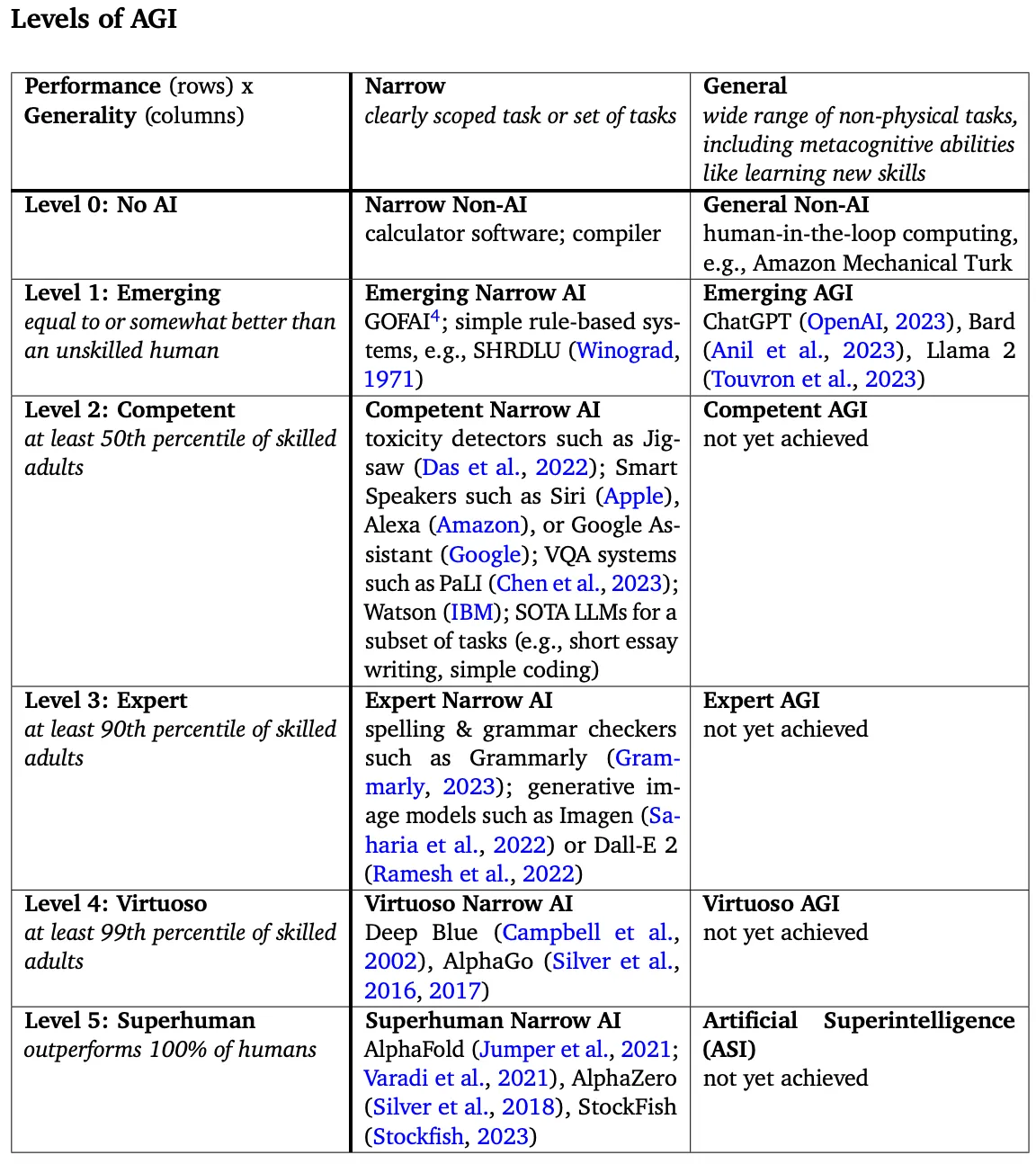 Image Source: DeepMind Paper
Image Source: DeepMind Paper
3. NVIDIA Go Brrr now everbody wants the juice
All this bullish rally on AI, who’s the real winner?
The past week’s drama has overshadowed NVIDIA’s remarkable financial performance. The figures are more than just numbers; they’re a testament to a transformative era where AI is not just a buzzword but a tangible driver of growth and innovation that are becoming a part of our everyday lives.
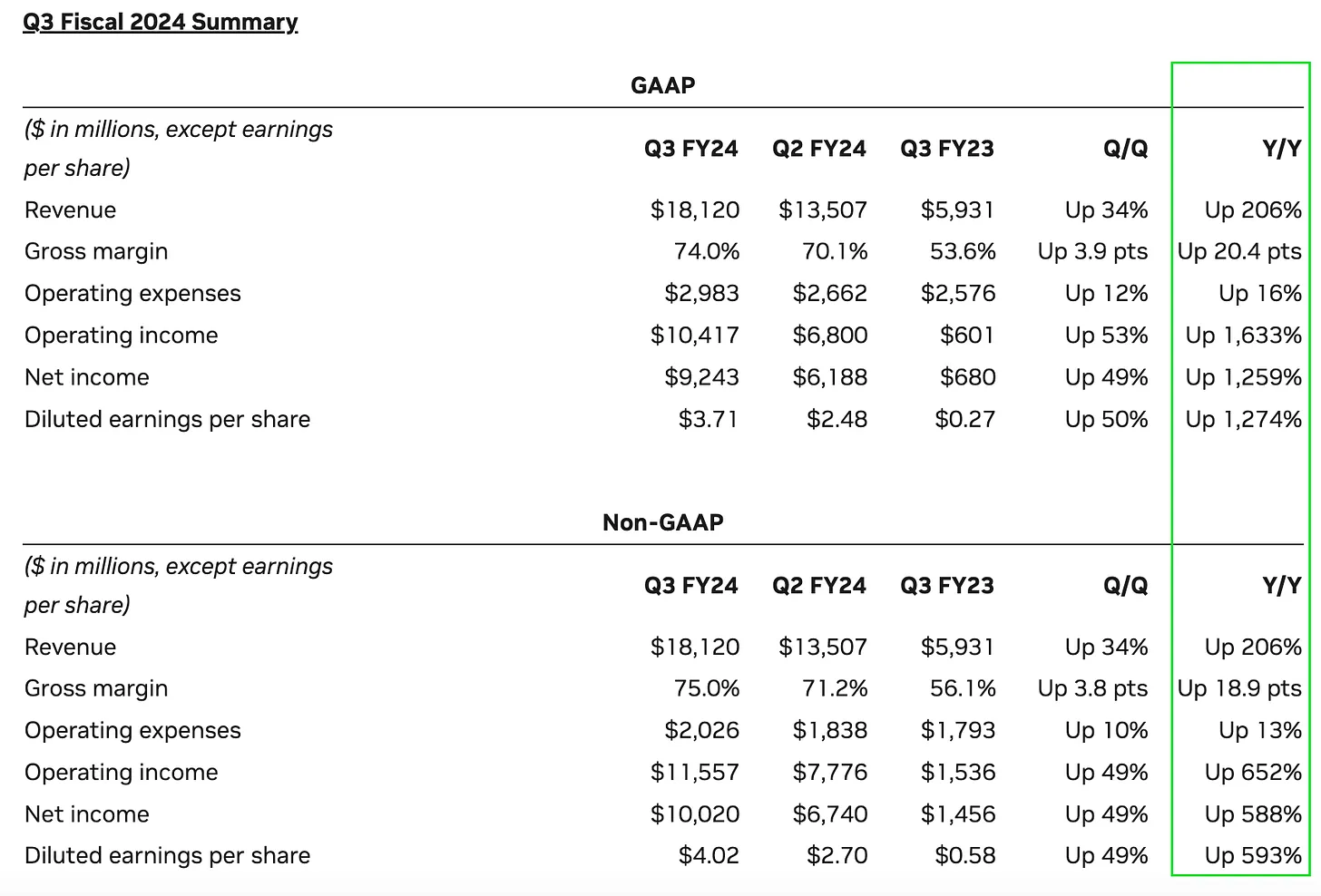
Speaking of the use of AI in our everyday lives. I tried to make ChatGPT (and even Bard) make the charts for distilling the insights from the above figures. After numerous attempts and a bit of tinkering, here are the results I’ve managed to achieve.
 Image Source: Personal Gallery. Generated by AI. So please don’t take it seriously
Image Source: Personal Gallery. Generated by AI. So please don’t take it seriously
Now, considering the state of AI, it seems we’re quite far from a truly “competent AGI” (as outlined in the Levels of AGI framework). If you put the charts created by AI side by side with those made by humans (below), the AI-generated charts appear rather basic.
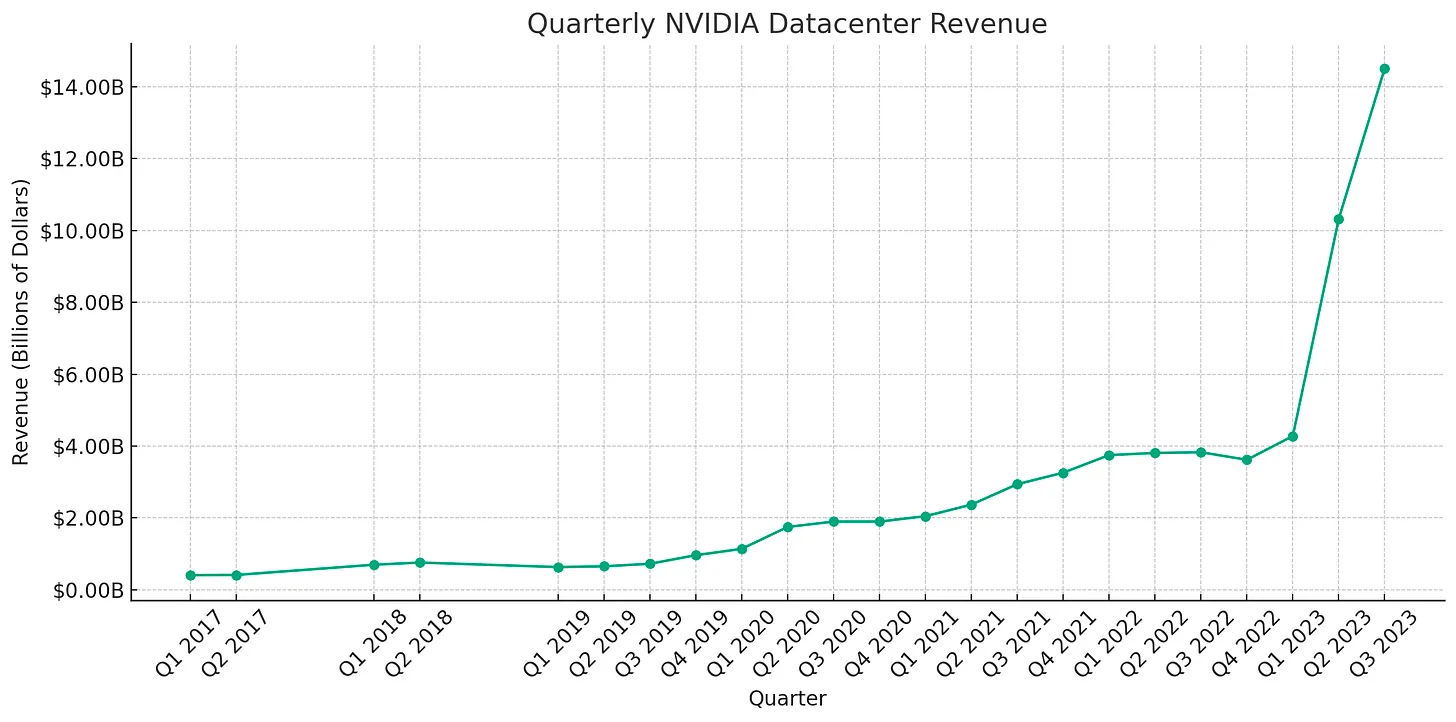 Image Source: Thomas Woodside
Image Source: Thomas Woodside
But in all seriousness, in the world where now our worth as challenger to the quest of achieving AGI is defined by whether or not we are GPU-rich or GPU-poor, which I think is reasonable, NVIDIA came out as the biggest winner in the space.
Thousands of companies and countries begged NVIDIA to purchase more GPUs to the point that the US Government imposed an export control - something that they usually do because of “national security” concerns.
If you think current sales are already big, you wouldn’t believe that it would be even bigger next year. NVIDIA is forecasted to sell over 3 million GPUs next year, about 3x their 2023 sales of about 1 million H100s. AMD is forecasting $2B of sales for their new MI300X datacenter GPU.
However, while NVIDIA’s dominance in the GPU market remains strong, there is a growing incentive and effort among major customers and new entrants to challenge this monopoly.
 Image Source: @absollutig
Image Source: @absollutig
Hyperscalers like Google, Microsoft, and Amazon are developing their own AI chips to cut costs and reduce dependence on NVIDIA. Google’s TPU, for example, may not match NVIDIA’s H100 in performance, but offers significant cost savings. To paint a picture, sourcing a H100 from NVIDIA would cost Google around $33,000.
Microsoft, collaborating with AMD, is working on the Athena project, while Amazon is exploring various AI strategies, including chip development.
AMD is positioning itself as a cost-effective alternative to NVIDIA, with its MI300 chip. However, the different software requirements for AMD’s chips pose challenges for widespread adoption.
Startups like Cerebras are also entering the market with innovative designs and potentially competitive performance, but face hurdles in gaining market trust and scaling production.
The post-production GPU market is evolving, with cloud providers offering GPUs on rent, but smaller companies seek more flexible rental options. Companies like CoreWeave and Lambda are filling this gap by providing variable access to GPUs.
Given the apparent link between increased computing power and advancements in artificial intelligence, it’s reasonable to expect that the demand for computing resources will continue to grow exponentially. There’s a chance that companies might put too much money into making big groups of GPUs—special computers used for AI—over the next few years, and they might end up with more than they actually need.
4. Claude 2.1 has been released
I’m a big fan of Anthropic and have been looking forward to try out the Claude API. However, I’ve not yet had the opportunity to use it. And now, they’ve released an updated version, Claude 2.1, boasting the ability to understand over 200,000 tokens of context. But how useful it is? Fortunately, this absolute legend on X conducted an extensive test, costing him $1,000 dollars and here I got to enjoy the insights:
- At 200K tokens (nearly 470 pages), Claude 2.1 was able to recall facts at some document depths
- Facts at the very top and very bottom of the document were recalled with nearly 100% accuracy
- Facts positioned at the top of the document were recalled with less performance than the bottom (similar to GPT-4)
- Starting at ~90K tokens, performance of recall at the bottom of the document started to get increasingly worse
- Performance at low context lengths was not guaranteed
 Image Source: @GregKamradt
Image Source: @GregKamradt
However, if we take a look at his previous test on GPT-4 with 128k context, the GPT-4 model seems to perform better than Claude 2.1.
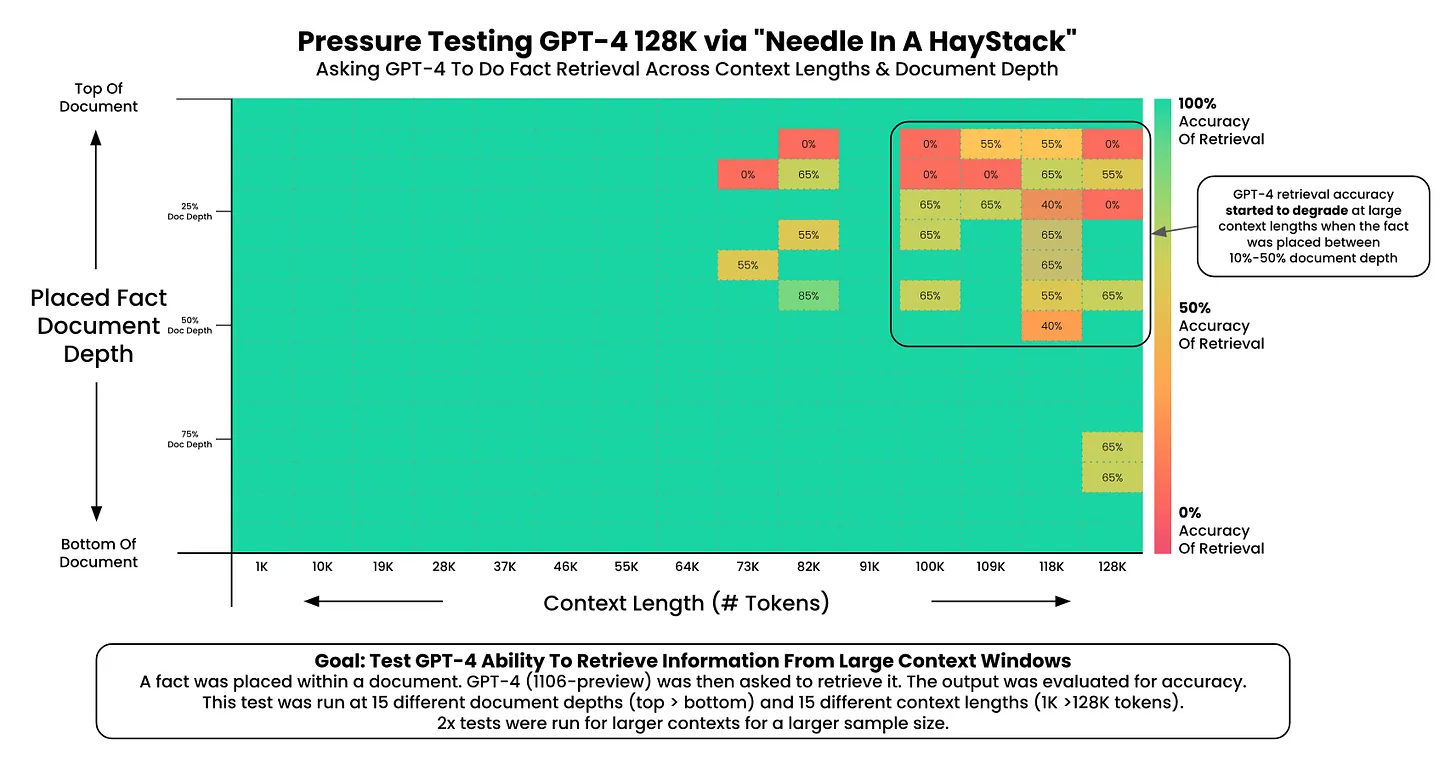
Image Source: @GregKamradt
I think from the above figures, we can say that:
- In shorter contexts, GPT-4 seems to outperform Claude-2.1 across various document depths.
- Both models exhibit reduced accuracy with longer contexts, but Claude-2.1 is more affected beyond 95K tokens.
- Claude-2.1 shows a steady decrease in accuracy with deeper document placement, whereas GPT-4 struggles more with facts in the middle.
- As the amount of data increases, both models struggle to maintain consistent performance, although this is more marked for Claude-2.1.
So all in all, GPT-4 is still the boss.